
Multisite processing starts where standard processing in one site ends. The following sections describes the supported multisite processing concept and the deliverable milestones to implement it.
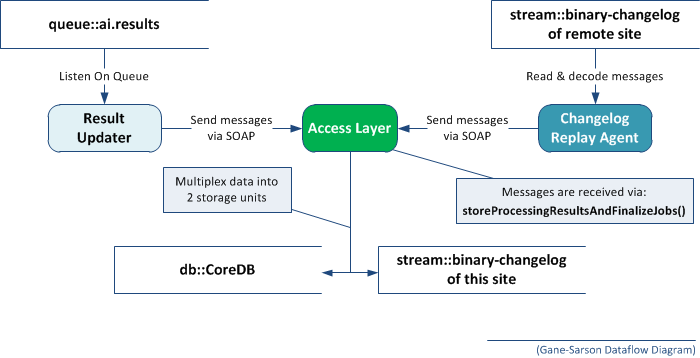
In short the concept behind multisite operations is to collect all final process package data sets of all Access Layers in one GRID site, write them to compressed binary logs and ship these log packages incrementally to all other GRID sites.
Diagram:
The technical details of the concept are:
See "Processing Elements" for more information on this.
With enabled multisite operations the content is additionally shared with all other running Access Layer instances using reliable multicast (using the same connections as also used by the distributed cache) and then logged into a ZIP package (on every connected ACL instance).
As every <processPackageDataSet/> element has a "processingSite" URI, the Access Layer will NOT log data sets that are originating from another GRID site. Therefore no endless message bouncing will happen under the assumption that the processingSite URIs differ on multiple GRID sites.
The scope of multisite operations is to transfer the processing results of the GRID including fresh processed content and re-processed content. When transferring this information, the implementations must be intelligent enough to avoid conflicts and duplications.
The actual file content behind the processing results is never subject of multisite replication. If there's a need to transfer this sort of content, then this simply has to be done as a manual transfer (taking into account that licensing restrictions may apply to such an exercise)
When collecting many <processPackageDataSet/> elements there needs to be a way to differentiate between them. Multiple options can be considered like: Using a XML wrapper document that contains the elements; Storing the elements in a custom chunked stream or finally using the file system to store every element in a separate file.
As one aim is to reduce resource requirements as much as possible, the single large document option is not useful. Creating a chunked stream can optimize resource usage but it requires a custom format definition. Using single files seems to the the best option but has one drawback when combined with a single ZIP package as ZIP has limitations and does not support solid compression (this means that the backing dictionary is not shared between files, leading to worse compression).
As many values inside the <processPackageDataSet/> elements are always the same, solid compression is mandatory to realize small transfer package sizes. Because of this the following approach is used:
The resulting ZIP package is fully standards compliant and can be hand-crafted for testing purposes. The concept does not advertise to use any sort of propritary standards.
coredb-updates-2010-05-21T13:45:00.zip
META-INF
manifest.mf
requires-packages: coredb-updates-2010-05-21T13:30:00.zip, ...
section-00001.zip
00000001.xml
00000002.xml
00000003.xml
...
section-00002.zip
00000001.xml
00000002.xml
00000003.xml
...
...
Basic replication requires that a single Access Layer instance is capable of writing a new ZIP package every "X" minutes and dump it into a defined output directory.
In addition a commandline line agent exists that can be used to replay the ZIP packages against an Access Layer instance.
If multiple Access Layer instances exist and are creating packages, every instance will need to write the output into a separate folder and all packages need to be collected, transferred and replayed using the agent (the replay can be done against one Access Layer instance).
Extends basic replication by the option to link multiple access layer instances using the distributed cache connections and therefore ensure that the incoming <processPackageDataSet/> element are evenly shared amongst all instances.
This has 2 advantages:
Automated replication extends the second milestone by running an additional agent that automatically keeps track of changes and transfers all changed packages from all other GRID sites that it knows.
Afterwards it will automatically call the replay agent. Implementing this concept allows to replicate GRID sites with no manual interaction.
Secured replication involves the signing and encrypting of the packages to ensure that the information is really coming from a valid GRID site.
This involves the Access Layers which need to be capable of sign and encrypt the packages and also the replay agent which needs to be able to validate and decrypt the content.